
How does DALL-E 2 by Open AI exactly work?
An AI system that can create realistic images and art from a description in natural language.


DALL-E 2 is an advanced artificial intelligence (AI) program developed by OpenAI that is capable of generating highly realistic and complex images from textual input. This breakthrough technology has gained widespread attention for its potential to revolutionize the field of computer-generated imagery (CGI) and transform the way we think about AI-generated art.
The name DALL-E is a combination of two famous artists: Salvador Dali and Pixar's Wall-E, reflecting the program's ability to combine creativity with cutting-edge technology. DALL-E 2 is a successor to the original DALL-E program, which was released by OpenAI in early 2021.
What sets DALL-E 2 apart is its ability to not only create entirely new images but also modify existing ones while retaining their key features. Additionally, it can generate variations of images and interpolate between two input images.
The impressive results generated by DALL-E 2 have left many people curious about the inner workings of this powerful model. In this article, we will delve deep into how DALL-E 2 creates such breathtaking images. Whether you are a seasoned machine learning expert or just beginning to explore this field, this article provides a comprehensive understanding of the DALL-E 2 architecture.
We will explore the background information necessary to understand DALL-E 2's architecture, and the explanations will be suitable for readers at various levels of machine learning experience. So, let's take a deep dive into DALL-E 2 and unravel the secrets of its incredible image-generation abilities.
How Does DALL-E 2 Work?
To begin understanding the inner workings of DALL-E 2, it's important to first have a broad understanding of how the program generates images. While it is capable of performing multiple tasks, such as image manipulation and interpolation, this article will specifically focus on the process of image generation.

DALL-E 2 is based on a type of AI known as a transformer network, which uses a process called deep learning to analyze and understand natural language input. The program is trained on a massive dataset of images and text, using a technique called supervised learning, in which the algorithm is given a set of input-output pairs and learns to generate similar output given the input.
When a user inputs a textual prompt into DALL-E 2, the program uses a series of neural networks to analyze the input and generate an image that closely matches the prompt. The process is highly complex and involves multiple layers of processing, including natural language processing (NLP) and computer vision.
First, the program analyzes the textual input using NLP algorithms to understand the meaning and context of the words. It then uses this information to generate a list of candidate image concepts that are related to the input. This process is known as "conceptualization," and it involves mapping the input text to a set of visual concepts that are likely to appear in the resulting image.
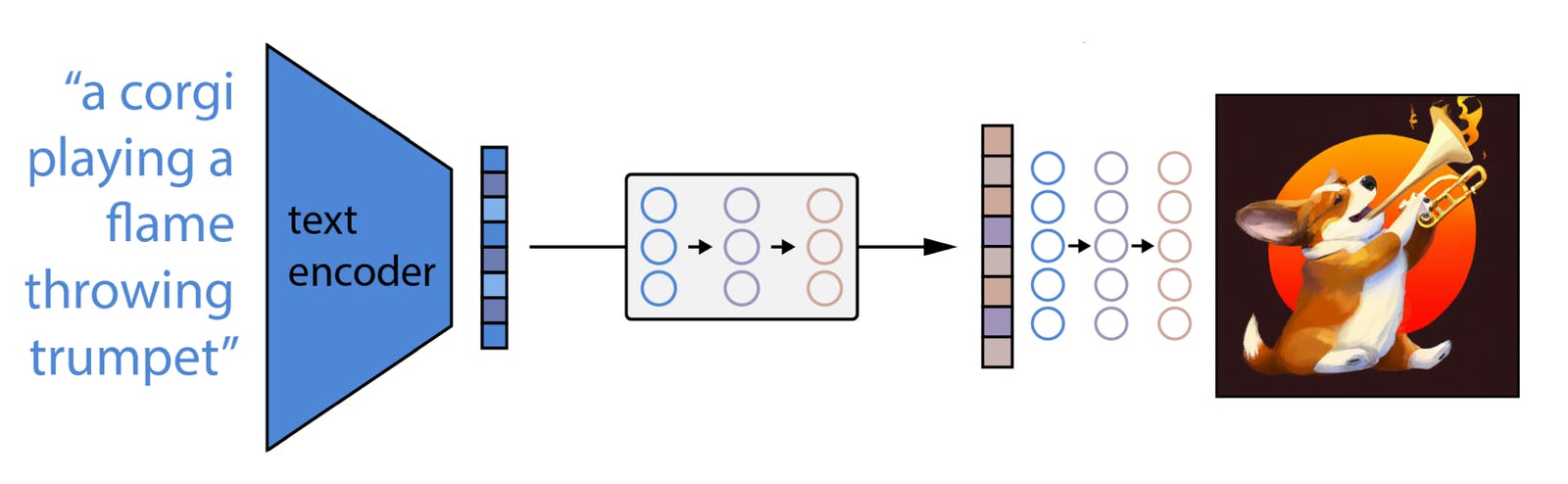
Once the program has generated a list of candidate concepts, it uses a series of computer vision algorithms to construct a visual representation of the input text. This process involves generating a series of "feature maps" that represent different aspects of the image, such as color, texture, and shape. These feature maps are then combined to create a final image that closely matches the input text.
One of the key features of DALL-E 2 is its ability to generate highly realistic and complex images that contain multiple objects and intricate details. The program achieves this by using a technique called the attention mechanism. This technique involves focusing on different parts of the input text and the visual representation at different stages of the image generation process. By doing so, the program is able to generate images that contain multiple objects and complex visual scenes.
To understand the overall functioning it's important to first understand the role of CLIP, another AI program developed by OpenAI. The text and image embeddings utilized by DALL·E 2 are derived from CLIP, which is designed to analyze and understand the relationship between images and natural language.
Understanding CLIP: Connecting Textual & Visual Information
CLIP is an advanced deep-learning model that has been trained on a massive dataset of images and corresponding text captions. Its objective is to learn how to match images to their respective textual descriptions. To achieve this, CLIP uses a technique called contrastive learning, where the model is trained to differentiate between positive image-caption pairs and negative ones, meaning image-caption pairs that don't match.
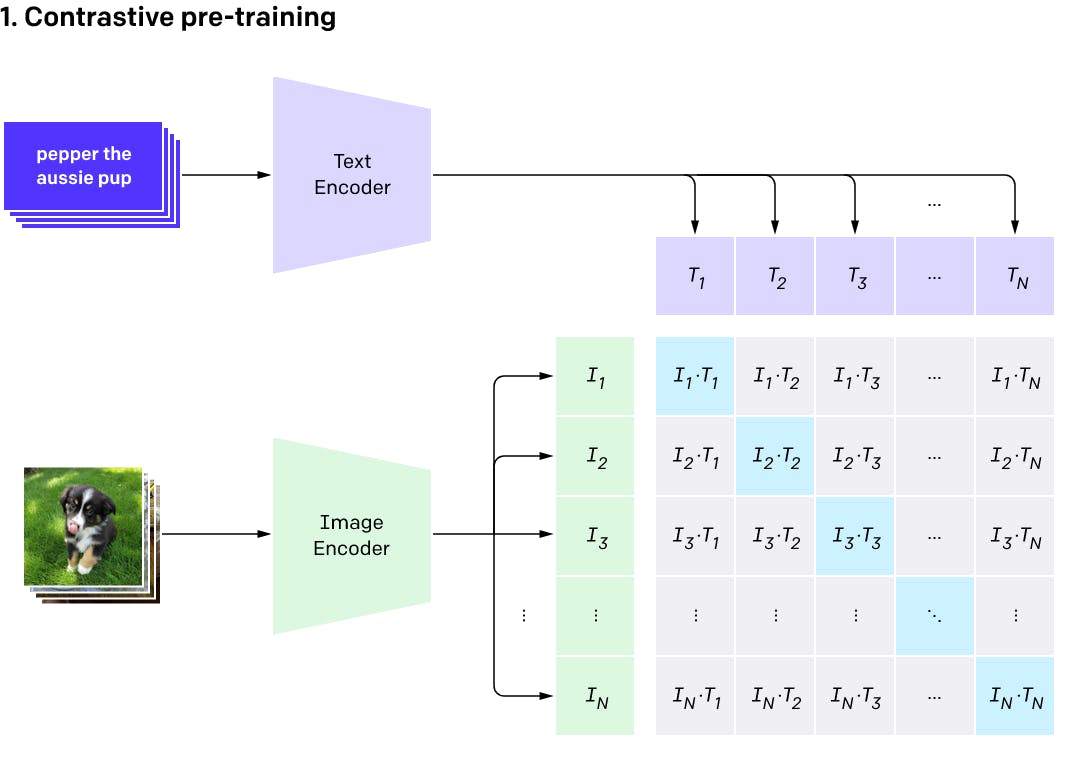
CLIP uses a transformer architecture similar to that of DALL·E 2, where the neural network is organized into layers of processing units that enable the program to analyze and understand complex relationships between images and text. The program's output is a set of embeddings, which are mathematical representations of the input text and image that can be used to compare their similarity.
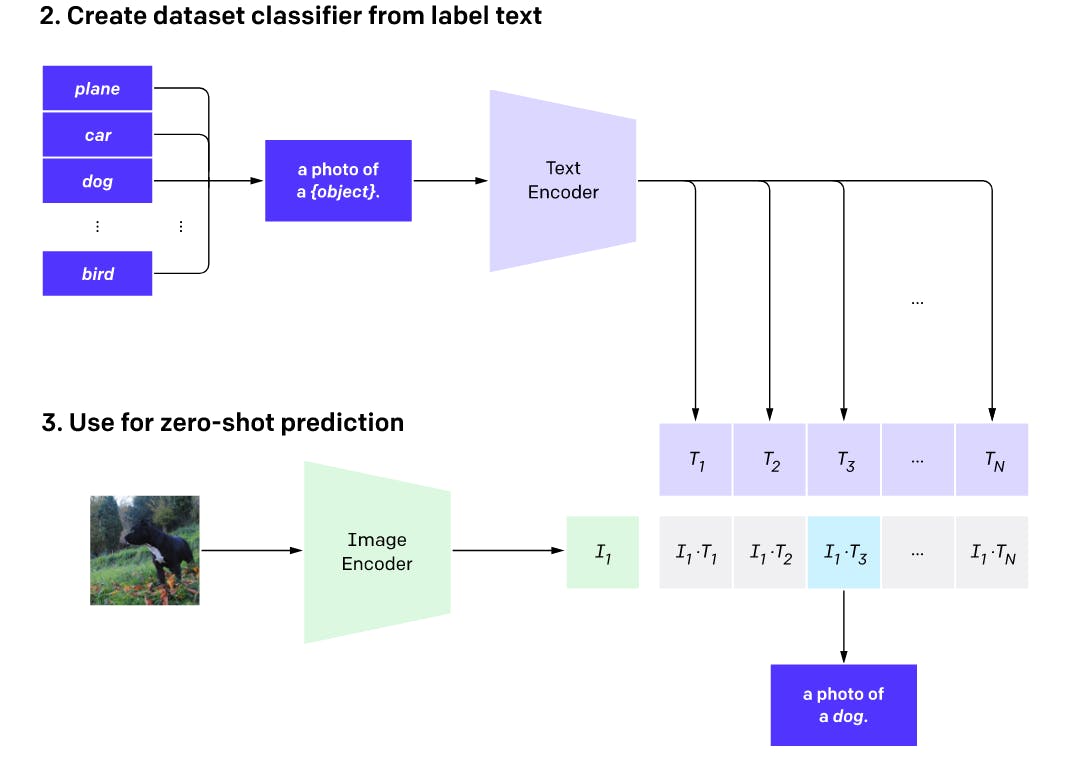
In DALL·E 2, the text embeddings generated by CLIP are used to conceptualize the input text and map it to visual concepts that the program can use to generate images. The image embeddings, on the other hand, are used to compare the generated images to the input text and ensure that the resulting image matches the prompt.
Although DALL-E 2 uses CLIP embeddings as intermediates for both text and image encoding it's not the CLIP encoder that generates image embeddings. Instead, DALL-E 2 employs a separate model, known as the "prior," to produce CLIP image embeddings based on the CLIP text encoder's embeddings.
The researchers behind DALL-E 2 explored two options for the prior model: an Autoregressive prior and a Diffusion prior. Both approaches showed similar results, but the Diffusion model was found to be more efficient in terms of computational resources. Therefore, it was chosen as the prior model for DALL-E 2.
For those unfamiliar with diffusion models, they are a type of generative model used in deep learning. They work by modelling the distribution of samples through a diffusion process that iteratively refines a set of noise vectors. This allows the model to generate high-quality samples that resemble the training data.
Applications of DALL-E 2
DALL-E 2 has a wide range of potential applications in various industries, including advertising, entertainment, and design. The program can be used to generate highly realistic and detailed images of products, characters, and environments, which can be used in advertising campaigns, movies, and video games.
In the field of product design, DALL-E 2 can be used to generate detailed 3D models of products, allowing designers to see how a product will look before it is even manufactured. This can help to streamline the design process and reduce the need for physical prototypes.
In the world of art, DALL-E 2 has the potential to revolutionize the way we think about computer-generated art. The program can be used to generate highly complex and creative images that are beyond the capabilities of traditional CGI techniques. This could open up new avenues of artistic expression and inspire a new generation of digital artists.
Summary
If viewed through the lens of research it reinforces the dominance of transformer models in handling large-scale datasets, thanks to the outstanding parallel processing capabilities. Moreover, DALL-E 2 serves as compelling proof of the efficacy of Diffusion Models, which are employed in both the prior and decoder networks of the program.
Finally, it underscores the dominance of transformer-based models for large-scale web-trained datasets as their exceptional parallel processing capabilities are further highlighted by the impressive performance of this AI program.
References:
Deep Unsupervised Learning using Nonequilibrium Thermodynamics
Generative Modeling by Estimating Gradients of the Data Distribution
Hierarchical Text-Conditional Image Generation with CLIP Latents
Learning Transferable Visual Models From Natural Language Supervision
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models